Meet LLMc: Beating All Compression with LLMs
This article is cross-posted from SyFI blog.
About a year ago, Baris posted a question in our group’s Slack asking whether we could build a compression/decompression engine with LLMs. After a few back and forths, Zihao (prior SyFI member, creator of FlashInfer, now at NVIDIA) pointed out that the problem is determinism. Kernels involved in transformers are highly non-deterministic; therefore, we’d need to first fix that “problem” before we can build effective compression. Thankfully, the great folks at Thinking Machines came to our rescue and defeated non-determinism in LLM inference.
Today Thinking Machines Lab is launching our research blog, Connectionism. Our first blog post is “Defeating Nondeterminism in LLM Inference”
— Thinking Machines (@thinkymachines) September 10, 2025
We believe that science is better when shared. Connectionism will cover topics as varied as our research is: from kernel numerics to… pic.twitter.com/jMFL3xt67C
Once we heard the story, another amazing SyFI member, Yi Pan, went after the question of whether we can build effective compression/decompression. A few hundred lines of code later, LLMc was born. LLMc uses LLM itself as a compressor for natural language. The model serves as a high-capacity probabilistic reference system, enabling compression based on token prediction and rank encoding. Initial tests reveal that its compression ratio beats anything out there.
Connection Between Language Models and Compression
Autoregressive decoding in LLMs parallels the decoding process in information theory. The source coding theorem [1] states that the optimal code length for a symbol is proportional to its negative log-likelihood. Thus, a model optimized for accurate prediction is inherently a candidate for data compression.
LLMc leverages this principle by converting the high-dimensional distribution of natural language into structured probabilities. Using the LLM’s in-context capabilities, it efficiently identifies high-likelihood token sequences and encodes them into a compact form.
Compression Mechanism
The core idea of LLMc is rank-based encoding. During inference, the LLM provides a probability distribution over possible next tokens. In most cases, the true next token ranks among the top few candidates. Instead of storing the token identity, LLMc stores its rank within the distribution. These ranks are small integers and therefore are compact to encode.
Decompression replays the same LLM with identical context. By applying the stored ranks at each step, the original text is reconstructed without loss. The model effectively acts as a shared reference between compression and decompression.
Performance
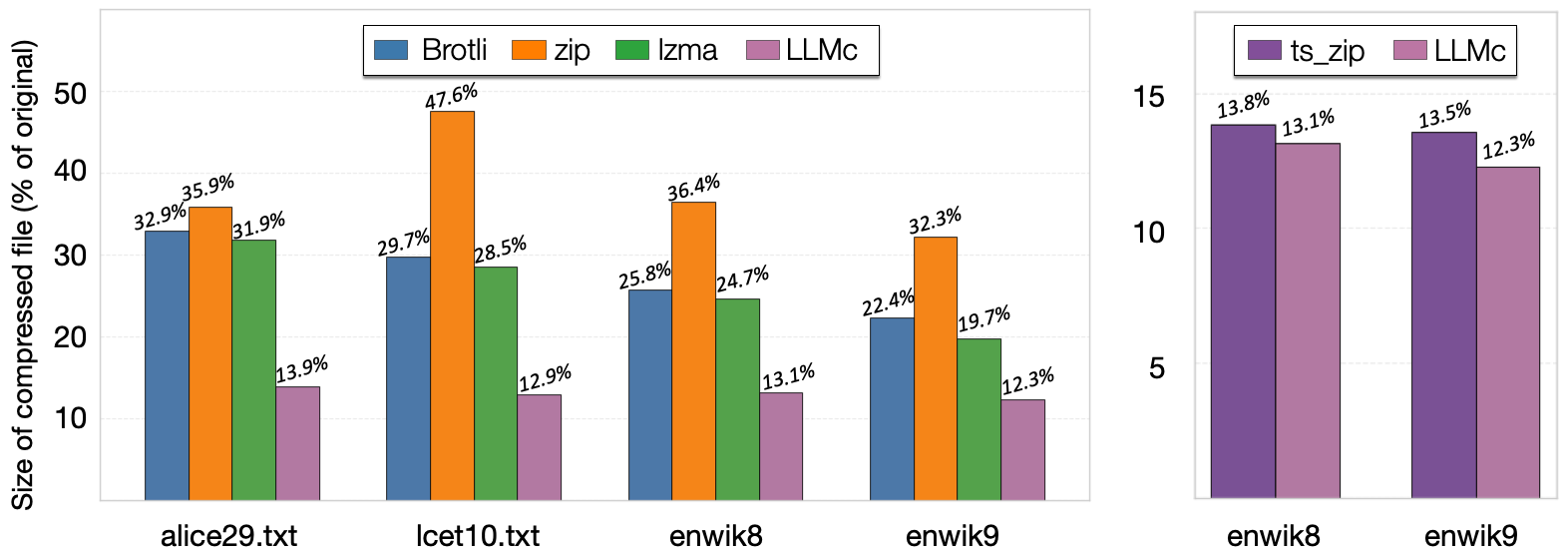
Benchmarks show that LLMc outperforms traditional compressors such as ZIP and LZMA across a range of datasets, including Wikipedia, narrative text, and scientific abstracts. It also achieves competitive or superior performance compared to other closed-source systems with similar objectives.
Efficiency Considerations
A primary challenge is efficiency. LLM inference has quadratic complexity with respect to sequence length, and long-context inference is memory-bound. To mitigate this, LLMc processes text in chunks. This improves GPU utilization during decoding and reduces the computational cost of prefill during compression.
Limitations
- Throughput is lower than conventional compressors due to reliance on large-scale model inference.
- Numerical stability requires specialized kernels (batch_invariant_ops) and integer encoding of token ranks, rather than direct log-prob encoding.
- The current implementation is designed for natural language; extension to other modalities (images, video, binary data) remains as future work (get in touch if interested).
Related Work
Prior studies have established the theoretical link between language modeling and compression [2]. Tools such as ts_zip [3] demonstrated similar concepts. LLMc is an open-source LLM-based compressor, and we look forward to contributions.
Contributors
This blog post was written by Baris Kasikci, Yi Pan, and Yibo Wu. LLMc also benefited from discussions with Zihao Ye, Haoran Peng, Hongtao Zhang and Dedong Xie.
References
[1] Shannon’s source coding theorem [2] Language Modeling Is Compression [3] ts_zip